
AI 越强,越需要管理者的真功夫——基于10万+场 Mr. Sen 管理模拟对练的数据洞察

管理没有被 AI 取代,只是被重新衡量
过去几个月,AI agent 的进化速度让人很难忽视。像 OpenClaw 这类工具的走红,把“AI 不只是回答问题,而是开始替你完成任务”的想象,突然变得具体:从整理信息到跨应用执行流程,一切都像按下了加速键。热潮之下,一个更现实的问题被反复提起——当 AI 能更快地产出方案、总结重点、推进流程,组织还需要多少管理者?
从表面上看,这个问题似乎指向“管理者会不会变少”,但在企业真实运行中,我们看到的趋势并不是管理消失了,而是管理在分化。那些主要依赖汇总信息、跟进流程、传递任务的事务型管理岗位,确实可能被压缩;但与此同时,真正负责统一理解、明确标准、压实责任、推动协同的管理工作,反而变得更加重要。
AI 让答案更便宜,却让对齐更昂贵。 当协作节奏变快、信息更加充分之后,真正拖慢组织的往往不再是缺方案,而是理解不一致、标准不一致、责任不一致。这样会导致的结果是:每个人都在忙碌,团队似乎一直在推进,但共识迟迟难以形成,执行也在反复偏航。
而共识如何产生,最终往往落在管理者每天最频繁、也最容易被低估的一项工作上:一次次对话。对话质量决定了问题能不能被说清,分歧能不能被化解,行动能不能被确认。
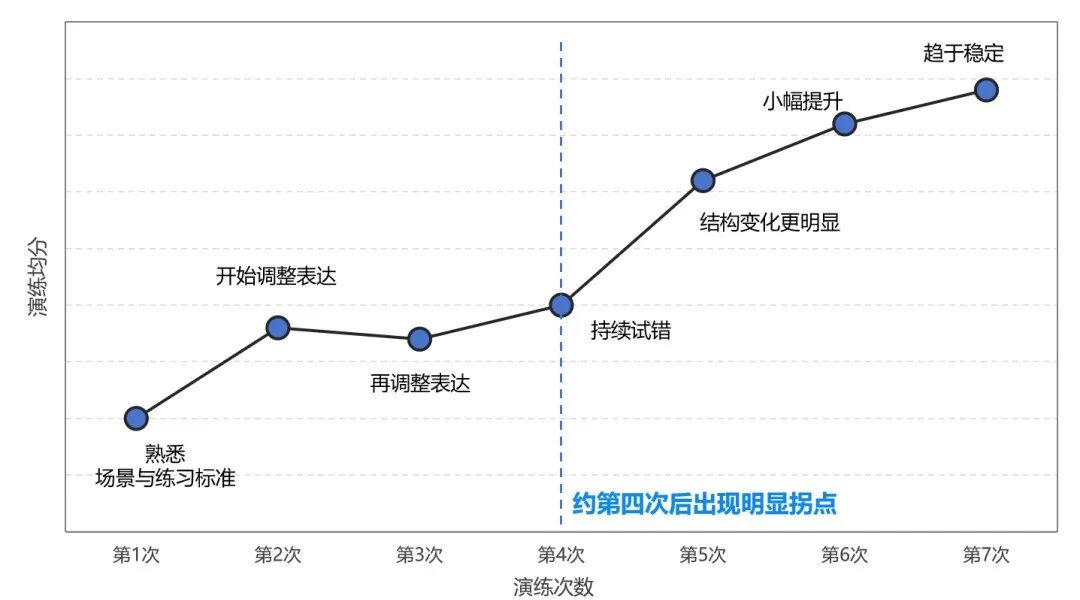
基于这一观察,本文从10万+场北森 AI 领导力教练 Mr. Sen 的管理模拟对练数据、也即真实管理情境中的对话行为出发,尝试回答一个更具体的问题:在 AI 时代,什么样的管理对话更可能真正推动事情向前?
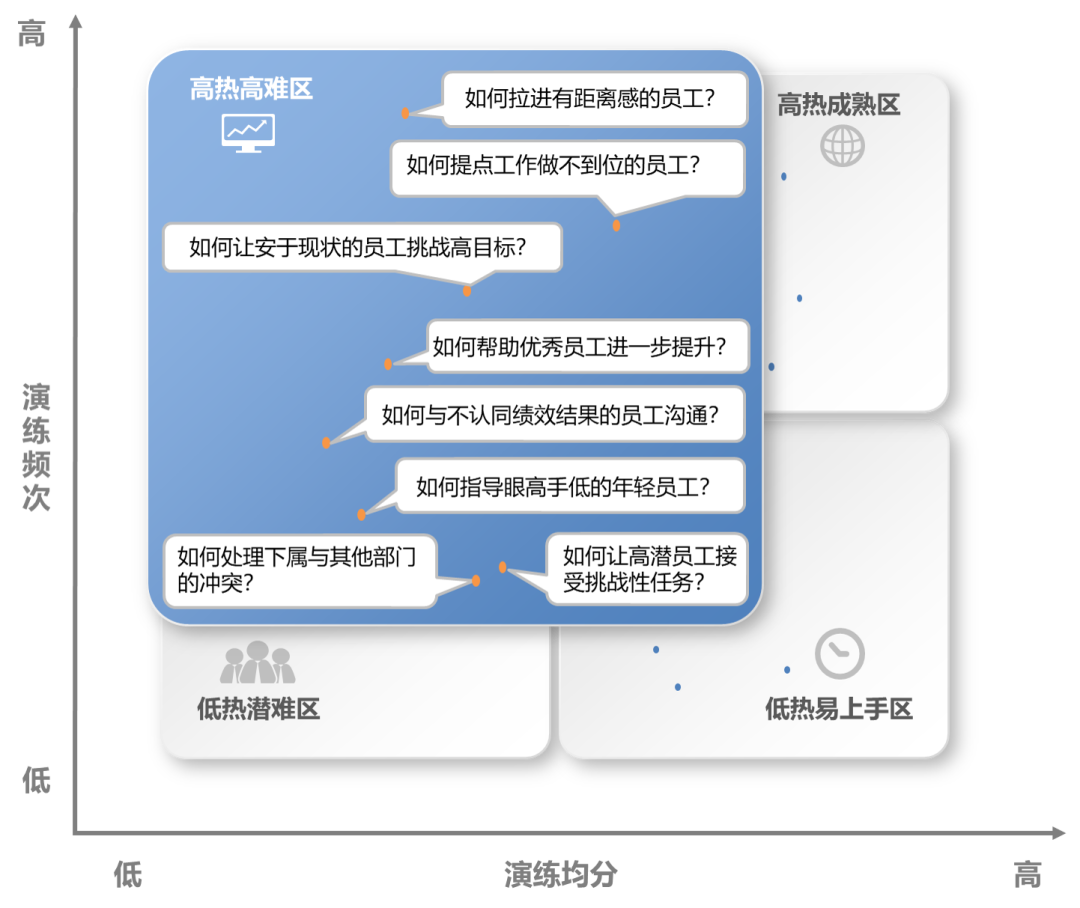
建立信任:如何拉近有距离感的员工? 推动执行:如何让安于现状的员工挑战高目标? 推动执行:如何让高潜员工接受挑战性任务? 推动执行:如何提点工作做不到位的员工? 辅导他人:如何指导眼高手低的年轻员工? 辅导他人:如何帮助优秀员工进一步提升? 沟通协调:如何处理下属与其他部门的冲突? 绩效辅导:如何与不认同绩效结果的员工沟通?
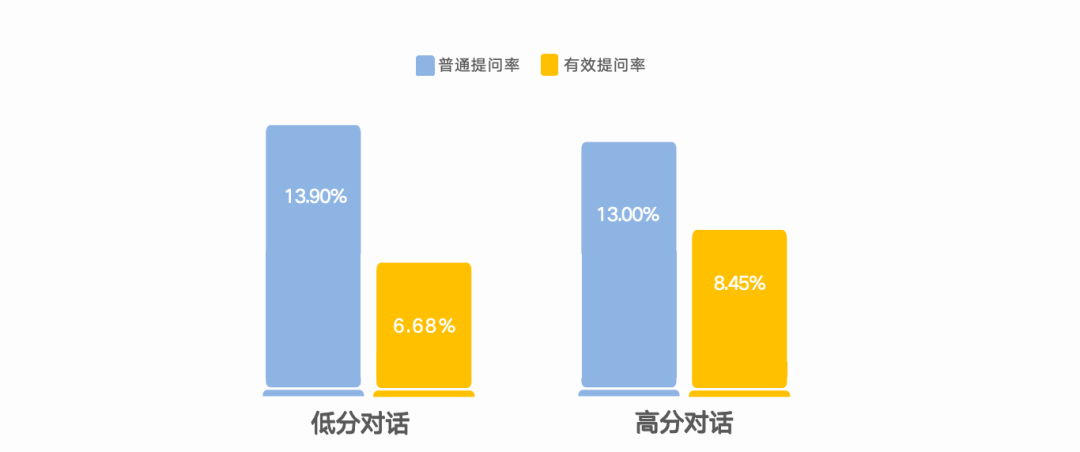
同样是提问,为什么会导向不同结果?关键不在“问没问”,而在“问完发生了什么”。低分对话的提问更容易停留在表层,甚至带着隐性评判,比如反复追问原因(“为什么会这样?”)、要求对方自我归因(你自己觉得问题到底在哪?”),对话随之陷入解释与辩护,问题并没有更接近解决。而高分对话的提问则更像“定位问题”,把抽象归因转向下一步的具体行动,比如卡在什么业务节点?是时间窗口、资源配置还是协作边界?先解决哪个堵点,下一步如何推进?
有效共情:决定对话能否继续推进的关键环节
在管理对话里,共情常被简单理解为“态度好一点、先表示理解”。但从大量对练对话来看,共情更像一个关键环节,它影响对方是否愿意说出真实顾虑,也影响对话能否回到共同解决问题。
从常见表达方式看,共情大致有两种形态。
一种是模板化共情,例如“我理解你”、“辛苦了”、“别多想”。这类表达本身无可厚非,但如果只是用来快速收住情绪,随后立刻进入要求或结论,对方往往会觉得“被安抚了,却没被真正理解”,甚至可能觉得在被敷衍。
另一种是有效共情,它先把对方的感受与触发点说清楚(“这确实让人委屈”、“如果是我,我也会……”、“我能想象……”),再把背后的担心或限制转化为可讨论的信息(“我们先把你最担心的点说清楚”),最后把讨论落到可验证的具体事项(“下周可以再复盘复盘”)上。它的作用不是停在安抚,而是把对话重新带回同一阵线。
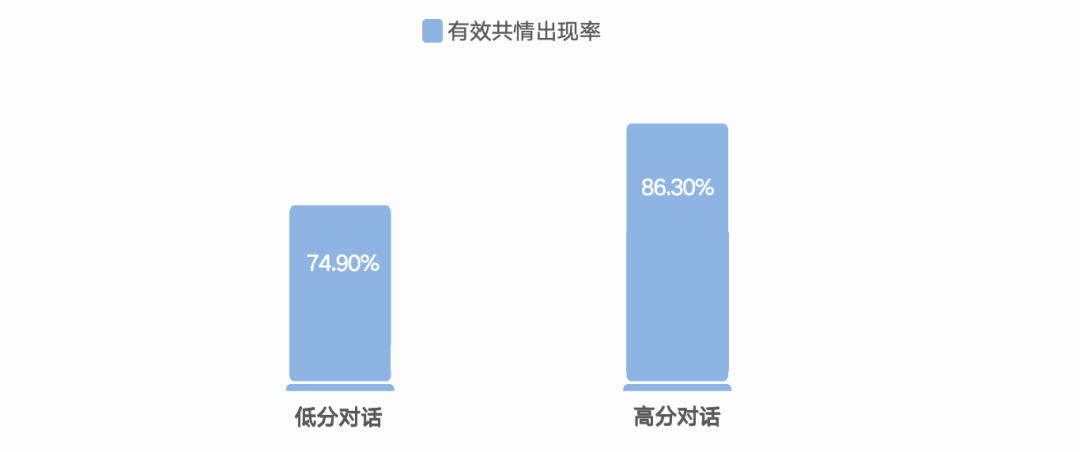
图3 不同类别的管理者在Mr. Sen管理模拟场景演练上的有效共情出现率对比图
数据也印证了这种差异:高分管理者在对话中出现有效共情的比例显著更高。这意味着,差距并不在于“会不会表达理解”,而在于能否把共情用成推进机制——把情绪转成信息,把顾虑转成议题,为后续对齐创造条件。这也是为何在数据中,“模板化共情”往往是对话崩盘的重要前兆——它会让对方觉得你只是在走流程,而非真诚对话。

相关文章
-
-

对标交流促提升|南京钢铁一行到访青岛特钢
对标交流促提升 近日,南京钢铁常务副总裁徐晓春率管理及生产技术团队到访青岛特钢。青岛特钢党委书记、总经理孙广亿,副总经理陈玉辉热情接待并参与交流。双方围绕行业趋势、产品优化、生产运营管理等议题展开深入对标与研讨。&...
2026-04-05 00:33:30 青岛特殊钢铁有限公司 -

坐标林芝,正式启航!广东建科所属总站公司西藏分公司揭牌运营
为积极响应国家援藏号召,深入践行国企使命担当,4月1日上午,广东建科所属广东省建设工程质量安全检测总站有限公司西藏分公司(以下简称“西藏分公司”)揭牌仪式在西藏林芝隆重举行,这标志着广东建科实施“西进战略”迈出了关键一步。广东建工控股党委书...
2026-04-05 00:18:50 广东建科院 -

中企出海|解读英国税收体系2026年最新变革
英国税收体系将于2026年迎来一系列重要调整。本轮变革涵盖企业税、间接税、关税、个人所得税等多个领域,政府同时在税收确定性与税务管理方面推出新的政策措施。相关调整将对个人、企业及投资者产生广泛而深远的影响。本文基于德勤英国资深专家根据实际项...
2026-04-04 22:18:26 德勤Deloitte -

3.20 世界口腔健康日丨优诺口腔第十届种牙节 以五维品质 筑“健康口腔” 享“幸福生活”
3.20世界口腔健康日优诺口腔第十届种牙节 以五维品质 筑“健康口腔” 享“幸福生活”每年3月20日,是世界口腔健康日,由世界牙科联盟(FDI)发起,旨在提高全球对口腔疾病预防和控制的认识。2026年,中华口腔医学会积极响应FDI...
2026-04-04 22:16:48 优诺口腔 -

直播预告|智慧物流整体解决方案——潜伏顶升+货架机器人专场直播!
撰稿:秦凯审核:李克忠批准:陈赛民往期推荐智慧物流 杭叉领创——杭叉集团在上海CeMAT ASIA 2025发布杭叉首款物流人形机器人,引领智慧物流新纪元杭叉集团|智造未来,匠心筑梦——杭叉集团2025年度技能比武大赛圆满落幕杭叉海外|杭叉...
2026-04-04 21:47:13 杭叉集团 -

专版产品|2027版《高考总复习优化设计·一轮》(江苏专版)AI赋能,个性化备考方案
专版编写理念YOUHUA SHEJI2027版紧扣江苏高考特点,在2026版基础上全面修订,贴合本省学情、教情、考情。1.专版专做,意行合一专属产品部专注研发,作者均为江苏一线名师,内容严格贴合江苏高考命题要求,适配本地备考。2.专版教研,...
2026-04-04 21:46:50 世纪天鸿 -

快速响应 高效攻坚丨护航云上业务稳定运行
当前,数字化转型迈入深水区,企业业务迭代加速,对云容量供给、资源高效配置及业务扩容的需求持续攀升,数据安全更是企业稳健发展的底线要求。作为数字化转型的核心支撑,紫光云公司始终坚守常态化主动运维、全方位安全防护、价值化运营三大核心服务能力,以...
2026-04-04 19:17:16 紫光云 -

-

5年前irr9%以上的承租人,现在要求4%以内了
关注#前海融资租赁俱乐部 ▶ 租赁精品课程、论坛、企业培训年卡 ▶ 领取行业报告来源 | 租赁小哥编辑 | 前海融资租赁俱乐部韦物5年前,承租人能承受的irr可以甚至最高到9%,当...
2026-04-04 15:01:26 前海融资租赁俱乐部



发表评论